テキストマイニングによる「持続可能性」の概念の整理
テキストマイニングによる「持続可能性」の概念の整理
東京情報大学総合情報学部 藤原丈史 櫻井尚子吉澤康介 三宅修平 鄭澤宇 高翔 山崎和子
はじめに
持続可能性(Sustainability),持続可能な発展(Sustainable Development)という言葉が広く使われるようになってきて久しいが,その概念に
ついては明確に定義されているわけではなく,さまざまなものが存在する.その中でもっともよく引用されるのは,ブルントラント委員会(1987年)
において定義された持続可能な発展の定義,すなわち,「将来の世代のニーズを満たす能力を損なうことなく,現在の世代のニーズを満たす発展」
である.しかしながら,この持続可能性,持続可能な発展という概念は,組織や個人,地域や国などによっても異なり,幅広い意味で受容できる定義
というのは今をもってないといえる.そこで本研究では,特に「持続可能な発展」という言葉が現在どのような概念として利用および広く受容されて
いるかを,インターネットにおける情報検索の結果を利用し,そこからテキストデータに対するデータマイニング技術であるテキストマイニング技術
を使って導き出すことを目標にした.
利用データ
本研究で対象としているデータは, "sustainable development"というキーワードに関してWeb検索した結果のデータである.その中でも,以下の3つの
データを分析対象とした.第1のデータは,Google Web検索エンジンで上記キーワードを検索した結果のWebページにおける各サイトごとのサマリー
テキスト文章である.第2のデータは,第1のデータとほぼ同じであるが検索サイトとして Google Scholar 検索エンジンを利用している.これは第1のデータが
一般的なWWW上で存在するWebページの情報を集約したものといえるのに対し,第2のデータは学術的な領域での情報を集約したものといえ,その対比を
見るためである.そして第3のデータは,第1のデータをより詳細に分析するためのもので,検索結果のWebページ一覧にある各サイトのWebページにアクセスし,
そのリンク先のページについてのテキストデータを対象とした.第1のデータがリンク先のWebページの一部(サマリー)を対象としていたのに対し,第3のデー
タはリンク先のWebページ全体を対象とすることで,よりキーワードに関する情報を網羅的に把握できる可能性がある.
分析結果
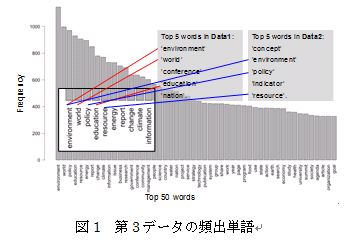
まずはそれぞれのデータについて,多く使われている単語を抽出しグラフ化した.図1は第3データについての頻出単語のグラフである
(第1データおよび第2データの頻出単語上位5個はグラフの欄外を参照).この結果では,頻出単語は各データによって異なるものの,"environment"については
3つのデータすべてで上位に位置しており,持続可能な発展の概念においては欠かせない要素になっているといえる.また,第3データの頻出単語上位5個は,
第1データと第2データの上位5個の組み合わせになっていることは興味深い.参考としてこの第3データについてのタグクラウド(頻出単語上位100個)を図2に示す.
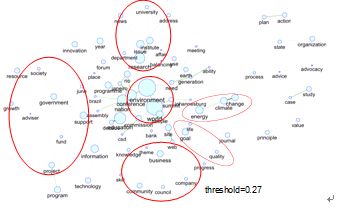
 次にネットワーク分析の結果を図3~5に示す.全体的にみると,これらネットワークは容易に理解できる形では単語間の関連をみることはできないが,ある程度
特徴的な部分はいくつか存在する.第1データ(図3)においては,まず中心となるのは "environment"と"world"であり,これらが概念として重要な位置づけで
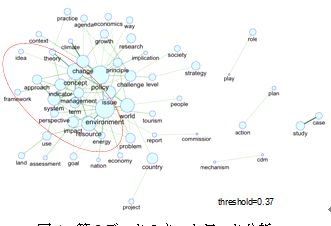
あることが分かる.さらにその周りとして,互いに関係する組織がサブネットワークを作っている.第2データ(図4)においては,第1データに比べ,より具体的
な単語がサブネットワークを形成している(例えば,"environment", "resource", "energy"のグループ,
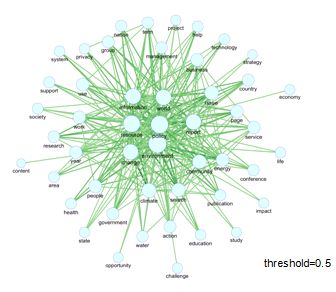
"management", "theory", "approach", "system", "framework"のグループなど).第3データ(図5)については,他の2つほどは特徴的な部分は見られない
ものの,"environment", "policy", "resource"が概念の中心的な役割を果たしているといえる.
次にネットワーク分析の結果を図3~5に示す.全体的にみると,これらネットワークは容易に理解できる形では単語間の関連をみることはできないが,ある程度
特徴的な部分はいくつか存在する.第1データ(図3)においては,まず中心となるのは "environment"と"world"であり,これらが概念として重要な位置づけで
あることが分かる.さらにその周りとして,互いに関係する組織がサブネットワークを作っている.第2データ(図4)においては,第1データに比べ,より具体的
な単語がサブネットワークを形成している(例えば,"environment", "resource", "energy"のグループ,
"management", "theory", "approach", "system", "framework"のグループなど).第3データ(図5)については,他の2つほどは特徴的な部分は見られない
ものの,"environment", "policy", "resource"が概念の中心的な役割を果たしているといえる.